Approach
This work is motivated by the need to ground task plans generated by LLMs in large-scale, multi-floor and multi-room environments. 3DSGs capture a rich topological and hierarchically-organised semantic graph representation of such environments with the versatility to encode the necessary information required for task planning including object state, predicates, affordances and attributes using natural language -- suitable for parsing by an LLM. We leverage a JSON representation of this graph as input to a pre-trained LLM, however, to ensure the scalability of the plans to larger scenes, we introduce two key components which exploit the hierarchical nature of 3DSGs: semantic search and iterative re-planning.
Semantic Search
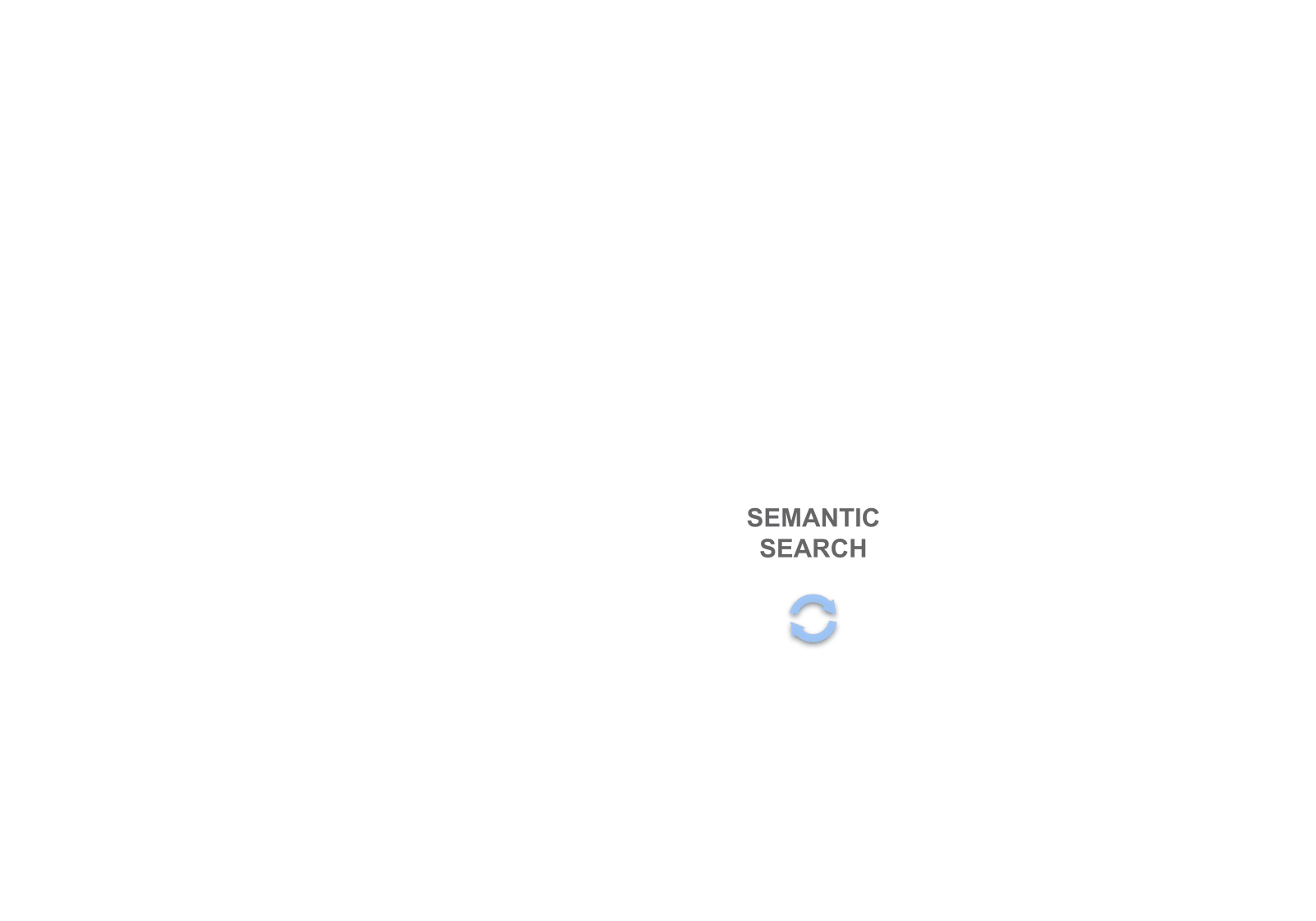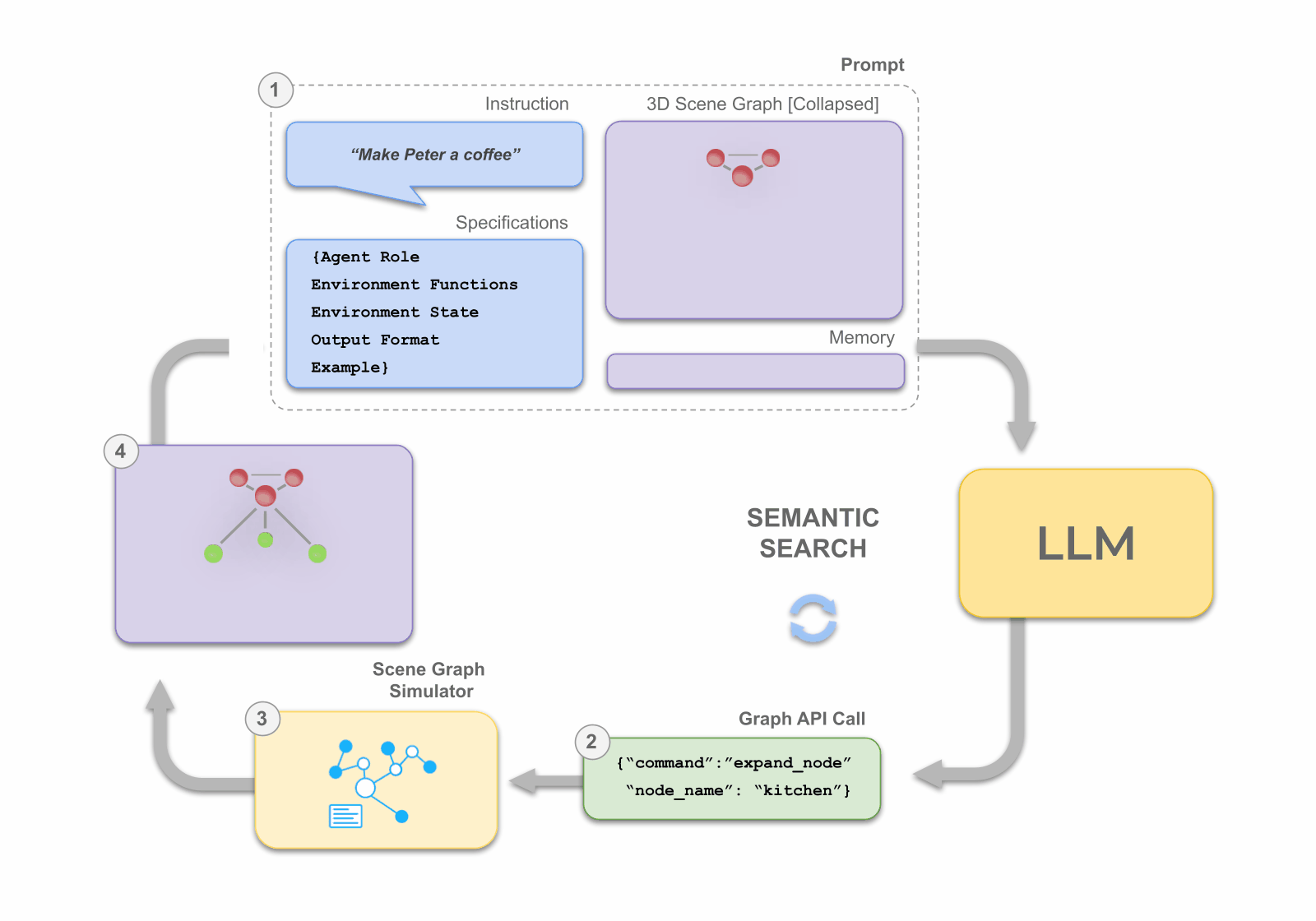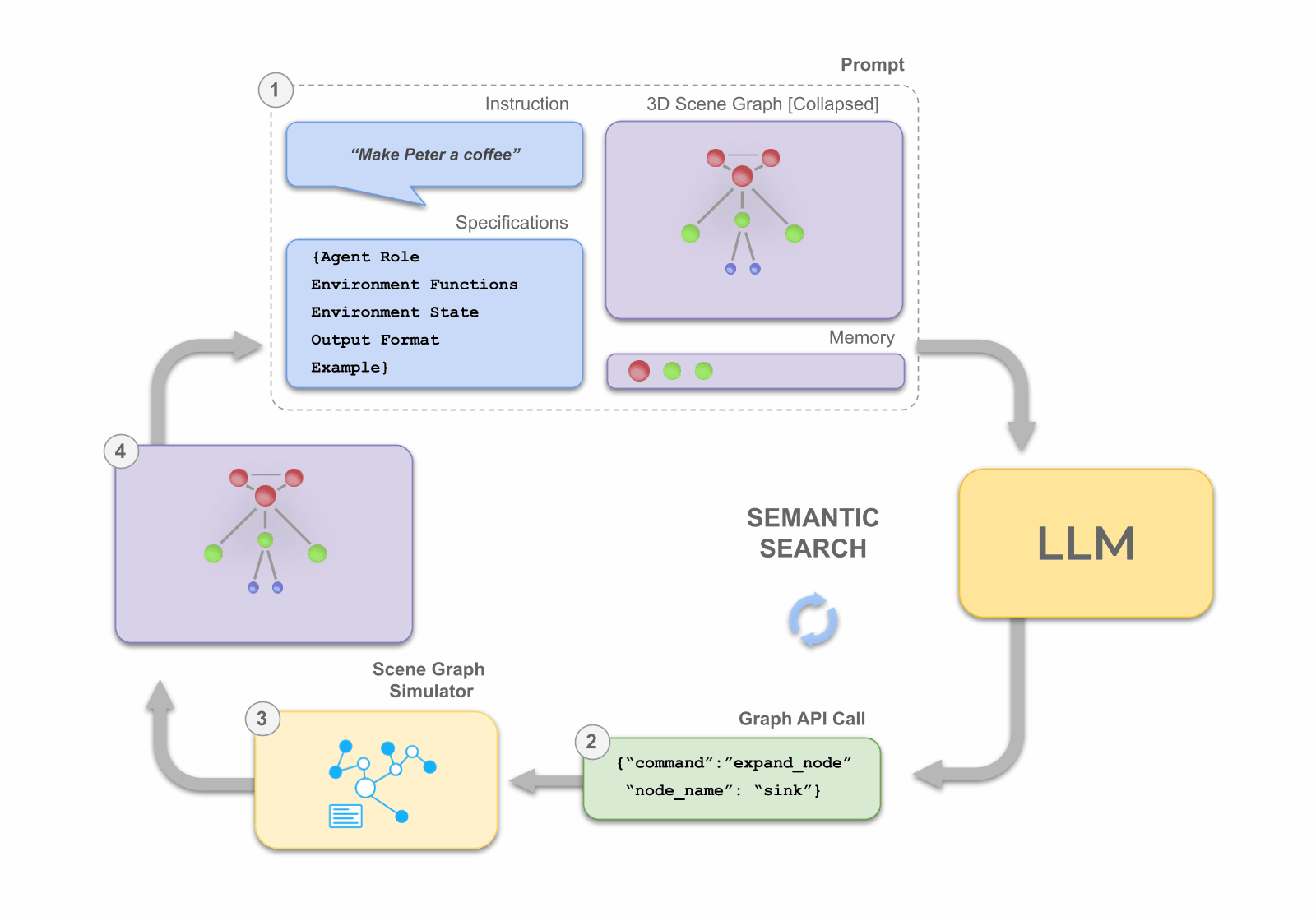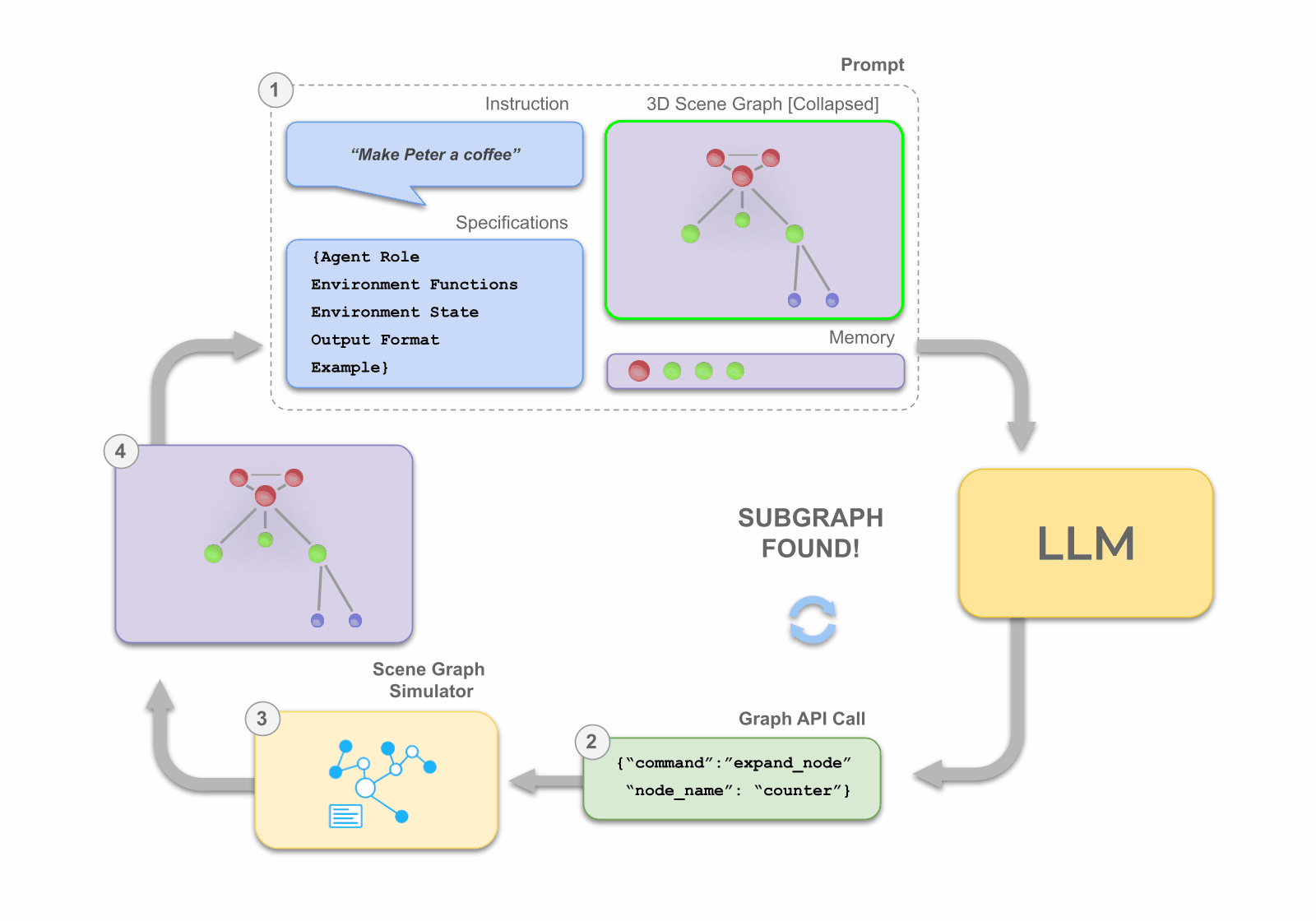
Given a natural language instruction, the LLM conducts a semantic search for a task-relevant subgraph which contains the assets and objects that are required for planning. This is done by manipulating the nodes of a collapsed 3D scene graph through expand and contract API function calls -- thus making it feasible to plan over increasingly large-scale environments. In doing so, the LLM maintains focus on the small, informative subgraph, during planning, without exceeding its token limit.
Iterative Re-planning
To ensure the executability of the proposed plan, we iteratively verify the plan using feedback from a scene graph simulator to correct for any unexecutable actions such as - missing to open the fridge before placing something into it; thus avoiding planning failures due to inconsistencies, hallucinations, or violations of the physical constraints imposed by the environment. We additionally relax the need for the LLM to produce long navigation sequences by incorporating an existing path planner such as Dijkstra to connect high-level nodes generated by the LLM.

Results
We demonstrate the ability to autonomously deploy the generated plan on a real mobile manipulator robot using a visually grounded motion controller. We utilise a pre-constructed 3D scene graph of an office floor spanning 36 rooms and containing 150 different assets and objects that the agent can interact with. Note the ability of the agent to generate grounded plans across multiple rooms. In all the videos shown, the robot operates fully autonomously using visual feedback from its in-hand camera for manipulation and localises itself within the scene graph using its onboard laser scanner.